TMVA Project in Machine Learning¶
Being a Machine learning enthusiast, I was overjoyed when my Google Summer of Code proposal to CERN SFT was accepted. My project involved lot of understanding and research in the field of Machine Learning. I designed and implemented various feature extraction methods in the TMVA toolkit. This blog post details the work I have been doing on this project for the past 4 months with CERN members.
About TMVA¶
The Toolkit for Multi Variate Analysis (TMVA) provides ROOT-integrated machine learning environment for processing and parallel evaluation of multivariate classification and regression techniques. TMVA is specifically designed to the needs of high-energy physics (HEP) applications. TMVA consists of object-oriented implementations in C++ for various multivariate methods and provides training, testing and performance evaluation algorithms and visualization scripts. The MVA training and testing is performed with the use of user-supplied data sets in form of ROOT trees or text files, where each event can have an individual weight. The true event classification or target value (for regression problems) in these data sets must be known. Preselection requirements and transformations can be applied on this data. TMVA supports the use of variable combinations and formulas.
TMVA Project Links
User Guide: http://tmva.sourceforge.net/docu/TMVAUsersGuide.pdf
Git repository: https://github.com/root-mirror/root
ROOT Reference Guide: https://root.cern.ch/doc/master/index.html
Mentors
Sergei V. Gleyzer, Programme administrator (Machine Learning), Research Scientist at University of Florida.
Lorenzo Moneta, Programme administrator (ROOT) and key maintainer of ROOT project.
Omar Zapata, Three times GSoC student at CERN and part of Summer Student Program at CERN.
Project Details¶
Before moving on to explain my project, I’d like to first introduce some basics of TMVA toolkit.
Features are called variables in TMVA toolkit.
Samples in a dataset are called events.
ROOT Trees are like spreadsheets which contain variables of different datatypes. They are stored in files with extension
.root.DataLoader contains all the information about dataset. It is passed to a Factory object which books, trains and tests all the classification and regression methods.
Following diagram shows the flow of a typical TMVA training and testing application.
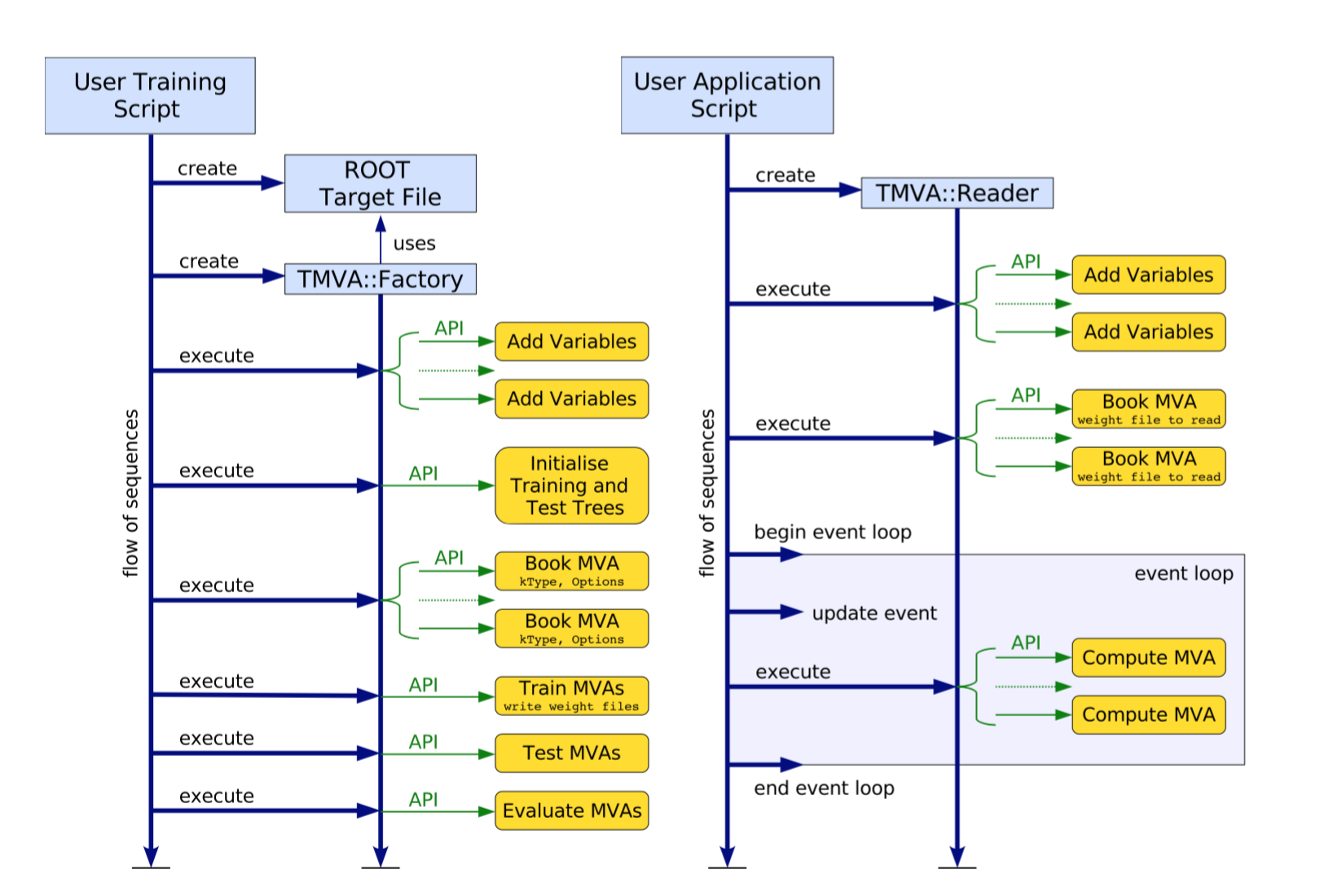
Source: TMVA User Guide¶
My project primarily focuses on implementing unsupervised feature extraction techniques in TMVA toolkit. Currently, the toolkit has only basic variable transformations techniques like Principal Component Analysis (PCA), Gaussian transformation, Normalisation, Decorrelation and Uniformisation. So I worked on implementing advanced variable transformation techniques which involved:
I obtained a thorough understanding of the research papers associated with this domain, following which I commenced the implementation.
User Interface¶
I created a new class VarTransformHandler, which handles, processes and executes all the variable transformation methods implemented. All these transformation methods are accessible by VarTransform method in DataLoader class and they all have a common format as below:
// VT stands for Variance Threshold
TMVA::DataLoader *newloader = loader->VarTransform("VT(option_string)");
// Autoencoder Transform
TMVA::DataLoader *newloader = loader->VarTransform("AE(option_string)");
// Feature Clustering
TMVA::DataLoader *newloader = loader->VarTransform("FC(option_string)");
// Hessian Local Linear Embedding
TMVA::DataLoader *newloader = loader->VarTransform("HLLE(option_string)");
option_string has different format according to each transformation method:
Variance Threshold - float value of variance, features with value above this threshold will be selected
Deep Autoencoder - Network layout and training strategy
Hessian Local Linear Embedding - Number of dimensions in the transformed data and number of nearest neighbours for building K-Nearest Neighbor graph (default is 12)
Feature Clustering - Number of dimensions in the transformed data
User will pass the required option_string to VarTransform method in DataLoader class. The VarTransform method would return a new DataLoader with the transformed variables and all the further analysis can be done using the new DataLoader.
Challenges and Work left¶
One of the biggest challenges I faced in the course of this project was understanding the mathematical aspects covered in the research paper, and converting them to the desired code. In order to get the intuition behind Deep Autoencoders, I did an online course on ‘Neural Networks for Machine Learning’ by Geoffrey Hinton, and read a few relevant research papers. I just had a basic idea of Deep Learning and Computational Neural Networks (CNNs), so this project really kicked me out of my comfort zone. In the start of GSoC official coding period, I was not able to setup Jupyter notebook environment with ROOT on Mac and it gave unexpected errors. So for the first two weeks of GSoC, I worked on Virtual Box with Ubuntu but it was really slow and things crashed unexpectedly. So it took me about a week to resolve all the issues and get things working on Mac OS X. It took time and effort to think of efficient designs, modifying them as per the need and solving the unforeseen bugs that crept in.
Till now, I have implemented Variance Threshold, Autoencoders (pre-training part left due to unexpected segmentation fault which is yet to be resolved) and Hessian Linear Local Embedding. I also understood the principles of Feature Clustering and tried to implement the same, but my implementation was hindered due to the presence of a theoretical limitation. I discussed the issue with my mentors and hopefully, we’ll find a way. I am making commits to my fork regularly and all my work will be merged at the end of GSoC period after discussion and review, as told by my mentor.
Relevant links¶
GSoC repository showcasing my work, consists of all the Jupyter notebooks and presentations
GSoC blog posts
Develop branch of my fork, which consists of all the commits made by me
Conclusion¶
Participating in Google Summer of Code has brought me closer to the ROOT and TMVA team, which comprises of an amazing group of programmers and scientists. The experience in working with them taught me essential soft skills like effective communication, designing for users and much more, than just writing code.
I would like to thank my mentors Sergei Gleyzer, Omar Zapata and Lorenzo Moneta for the support and help they provided. They were always there and weekly meetings over Skype and Vidyo really helped me to keep track of project and kept me motivated. I learnt a lot from this project and I’ll keep contributing and help wherever I can, to keep the TMVA toolkit updated.
Thanks you Google and CERN SFT, for providing me with this bright opportunity!
