Autoencoders Implementation Design II¶
In this post, I’ll discuss in detail about the design and implementation of Autoencoder transformation in TMVA. I am making all the changes in the branch develop (initially it was autoencoder, I renamed it) of my fork. I’ll be adding all the new features in this branch only. All the code can later be merged from this branch.
User Interface¶
All the variable transformations implemented by me will be there in the DataLoader class. They are accessible by VarTransform method in DataLoader class. All of them will be having a general framework as below:
TMVA::DataLoader *newloader = loader->VarTransform("VT(option_string)"); // VT stands for Variance Threshold
TMVA::DataLoader *newloader = loader->VarTransform("AE(option_string)"); // Autoencoder Transform
TMVA::DataLoader *newloader = loader->VarTransform("HC(option_string)"); // Hierarchial Clustering
TMVA::DataLoader *newloader = loader->VarTransform("LLE(option_string)"); // Local Linear Embedding
option_string has different format according to each transformation method. In Variance Threshold transformation, it was just a float threshold value.
Before discussing format of option_string in Autoencoder transform, I’d like to state a point. I am using the DNN namespace of TMVA. In DNN namespace, we have the option to setup layout and training strategy of network. In layout part, we can’t setup the whole network. We have the freedom to set number of nodes and activation functions for hidden layers but NOT input and output. Input values are fetched from variables added to DataLoader and number of output nodes are decided by the type of problem we are trying to deal with. If it’s a classification problem, then it’d have number of nodes equal to number of classes. On the other hand, if it’s a regression problem, number of nodes are decided by number of target variables added to DataLoader.
option_string in Autoencoder transform have the following format:
indexLayer=some_integer;layout_and_training_strategy_of_dnn
Autoencoder is basically a deep neural network where we set the targets or output values as input variables and the network learns some useful features in hidden layer. I give the freedom to user to setup the deep neural network or autoencoder according to their need. Again stating, in layout we can only set the activation functions and number of nodes for hidden layers and I set the target nodes as input variables internally. indexLayer denotes the layer number (0 is input layer, 1 is first hidden layer and so on) whose node activation values will be treated as new transformed variables. Basically it’s a multi value regression and I am training the network by backpropagation. After training is over, I return the new DataLoader with activation values of indexLayer (which is some hidden layer) as new transformed variables.
I couldn’t train the DNN in Jupyter notebook, so below are screenshots of console output in ROOT interpreter which a user gets when Autoencoder transformation is being performed.
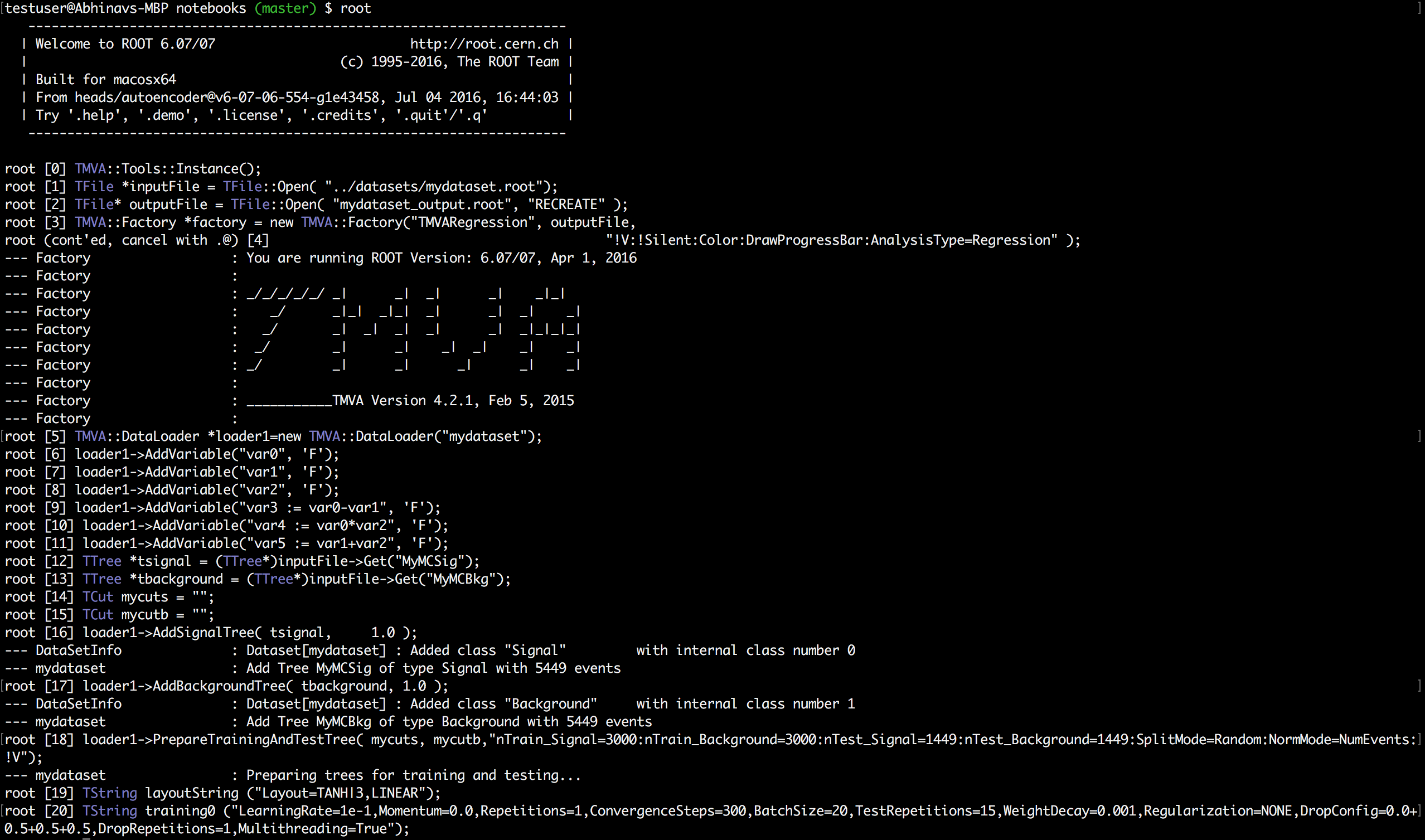
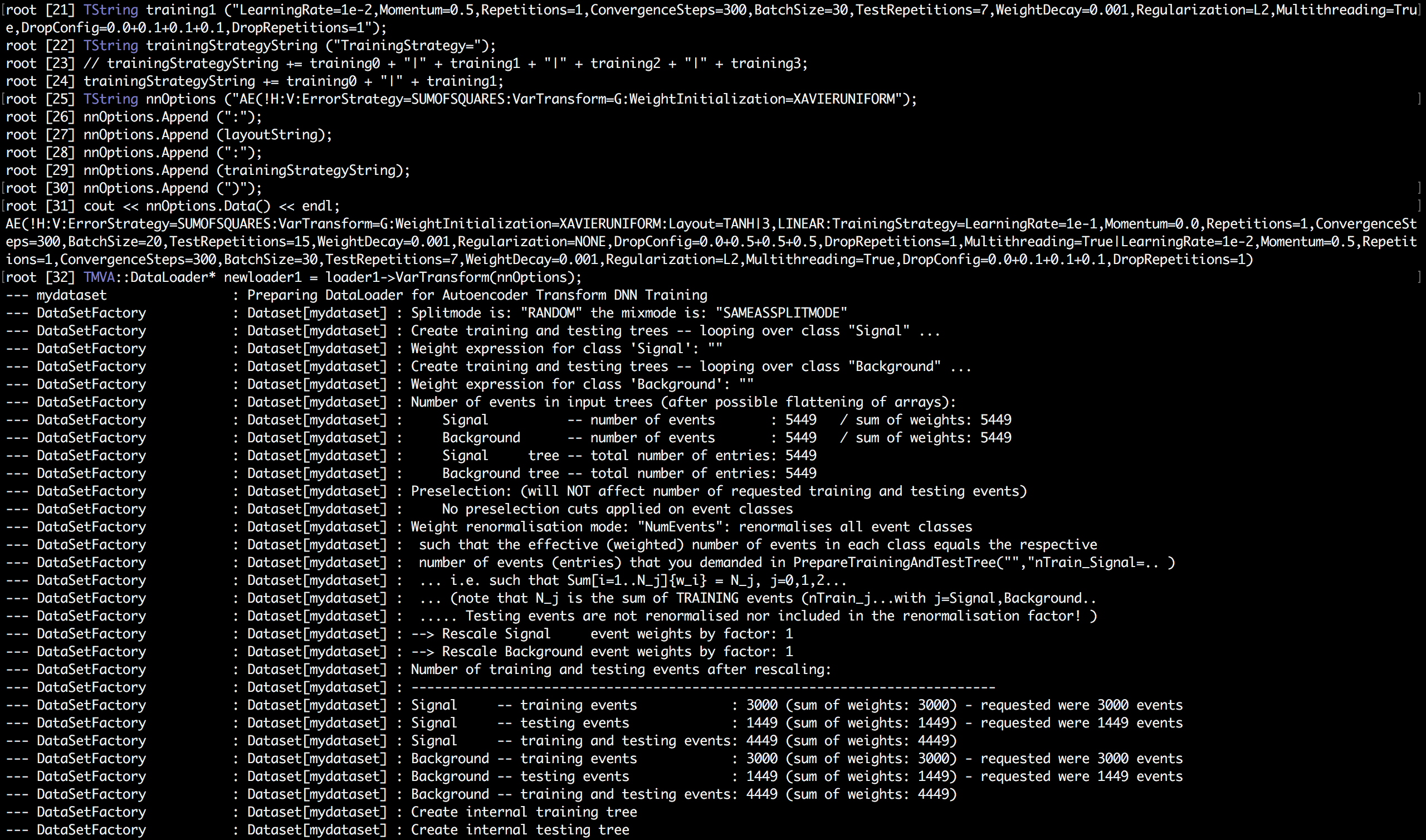
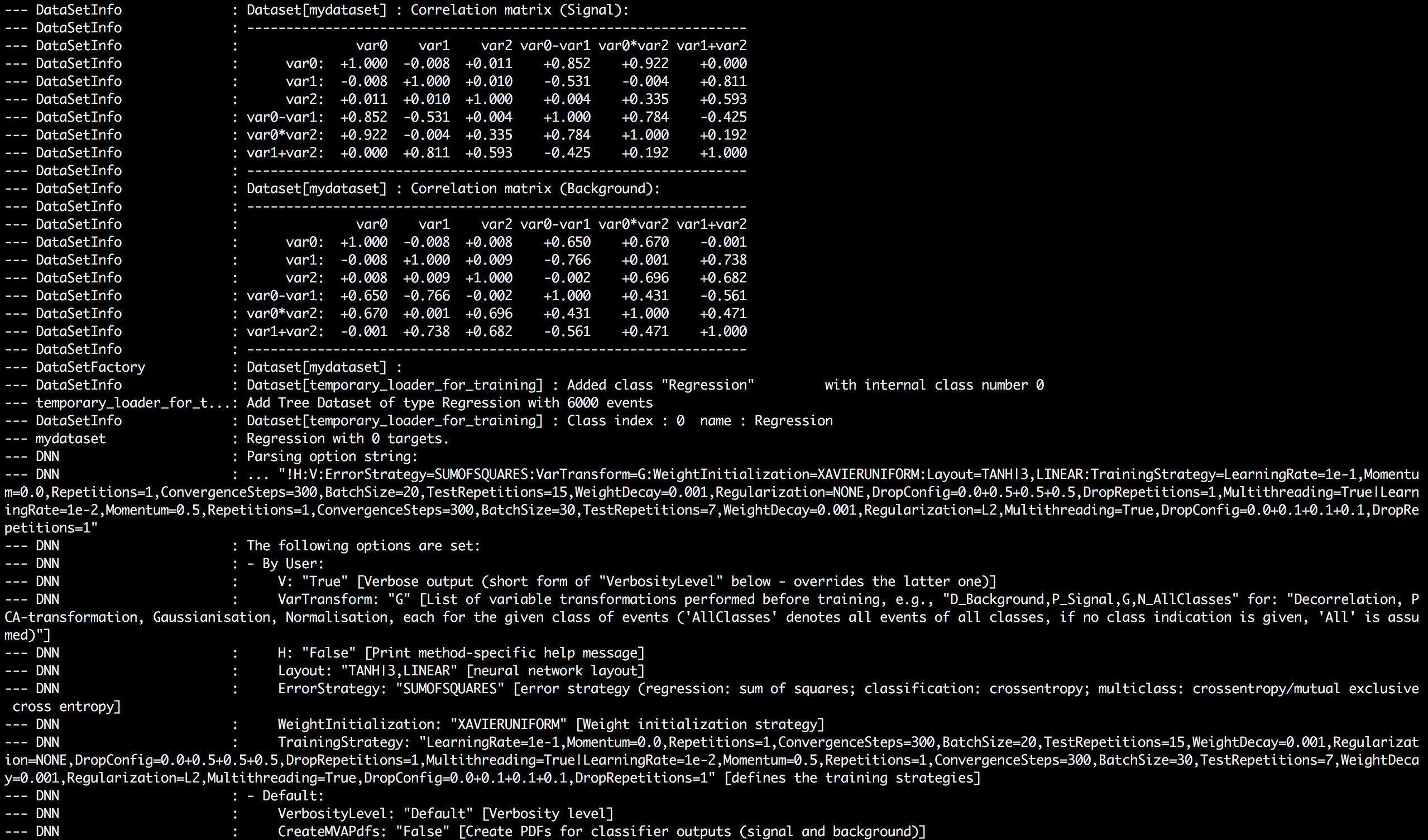
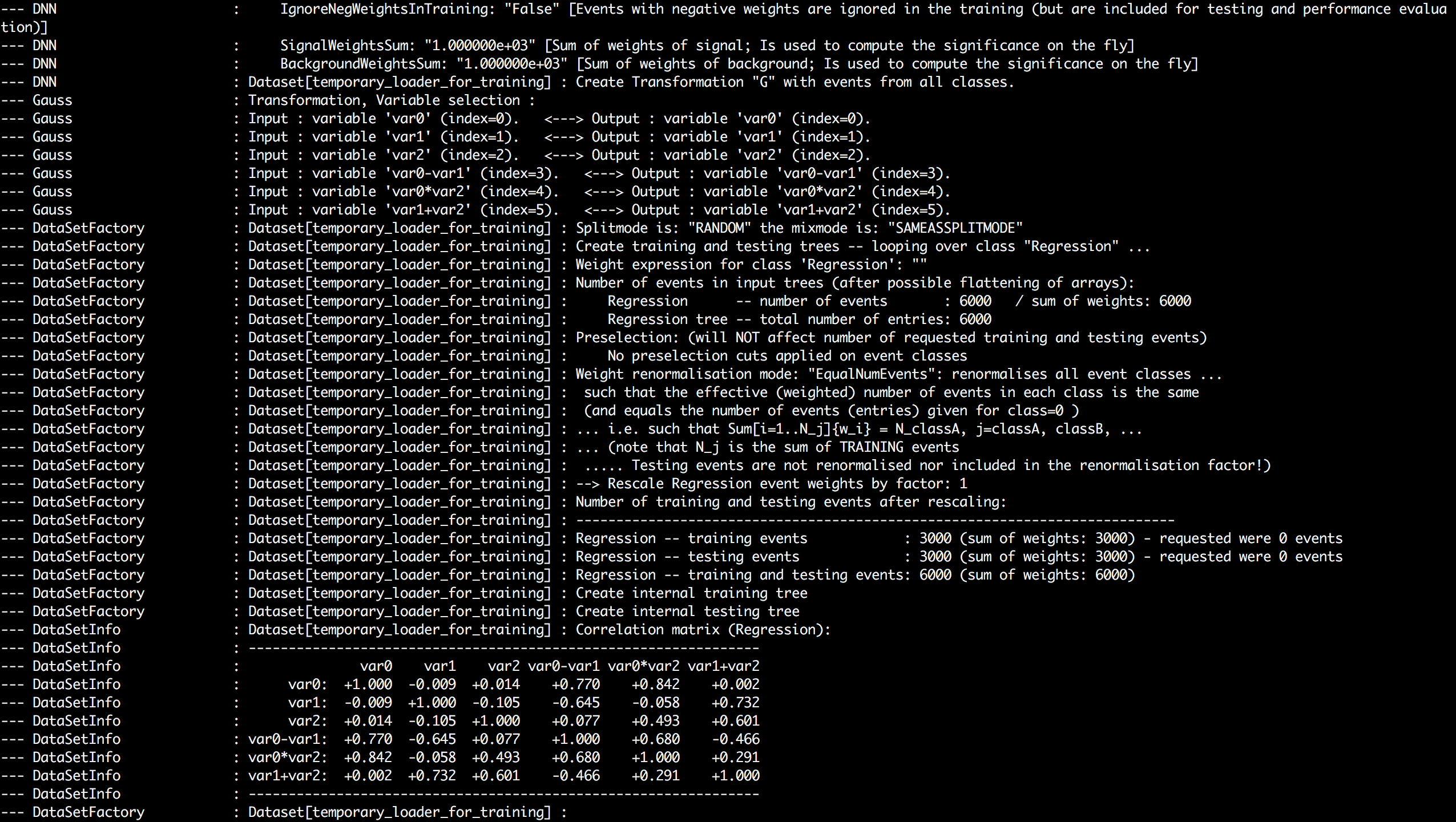
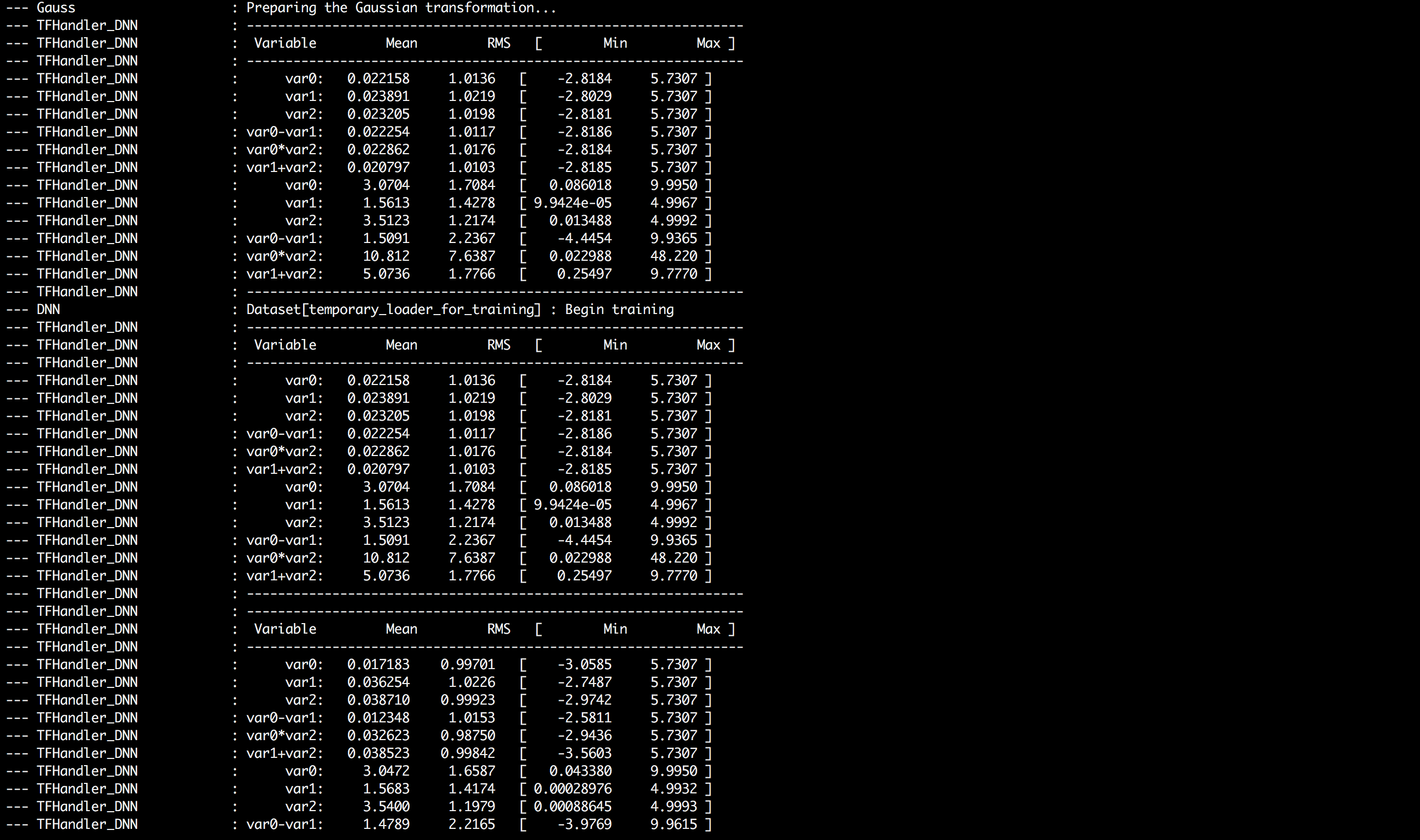
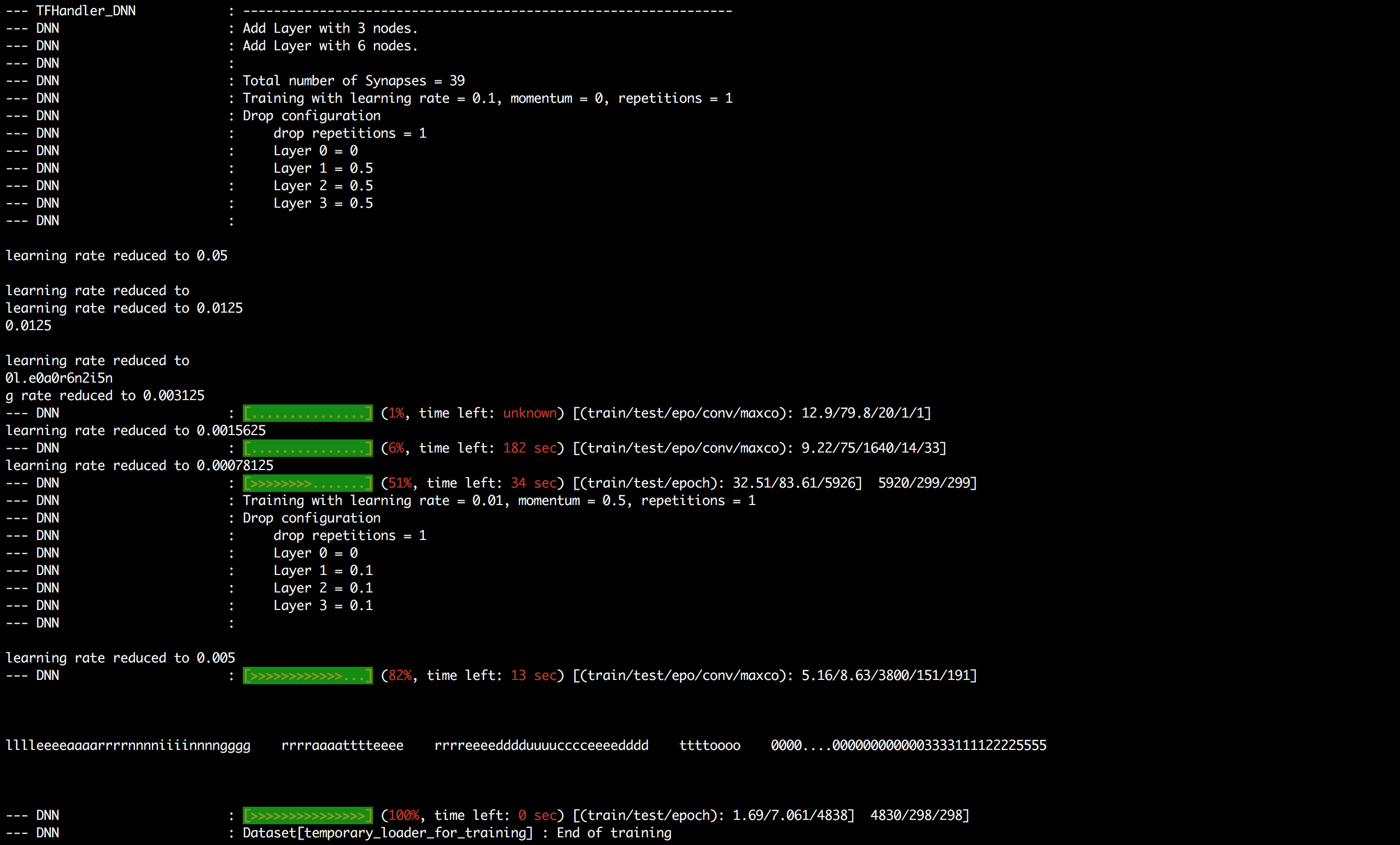
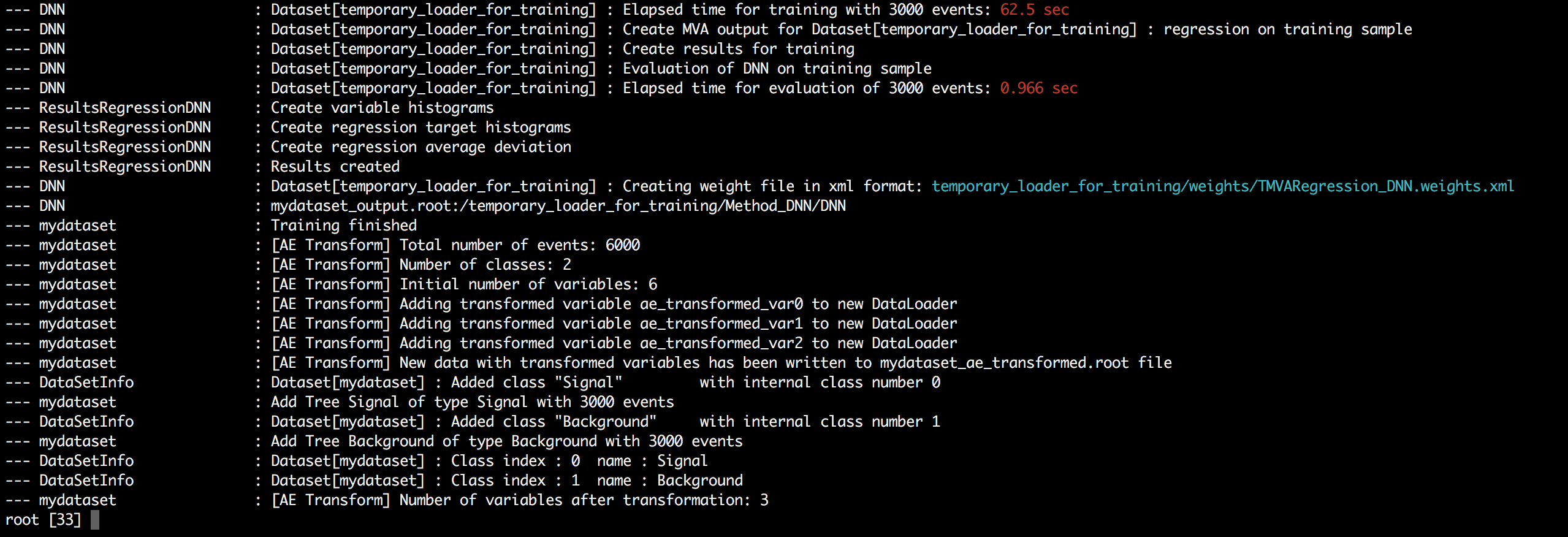
I haven’t implemented the interface for indexLayer in option_string yet. It’s hard coded as 1 i.e. first hidden layer. The last line of console output states that number of variables after transformation is equal to 3.

It is because I am using activation values of first hidden layer which has 3 nodes as we had set earlier in the layout string.

I am also looking forward to add the option of pre-training as true or false. option-string will look like:
indexLayer=some_integer;pretraining=true;layout_and_training_strategy_of_dnn
If set to true, pre-training procedure would be followed and weights would be set, upon which backpropagation will be performed later. If false, it’d follow the current procedure.
Implementation Design¶
Following diagram sums up all the changes made and reasons behind them.
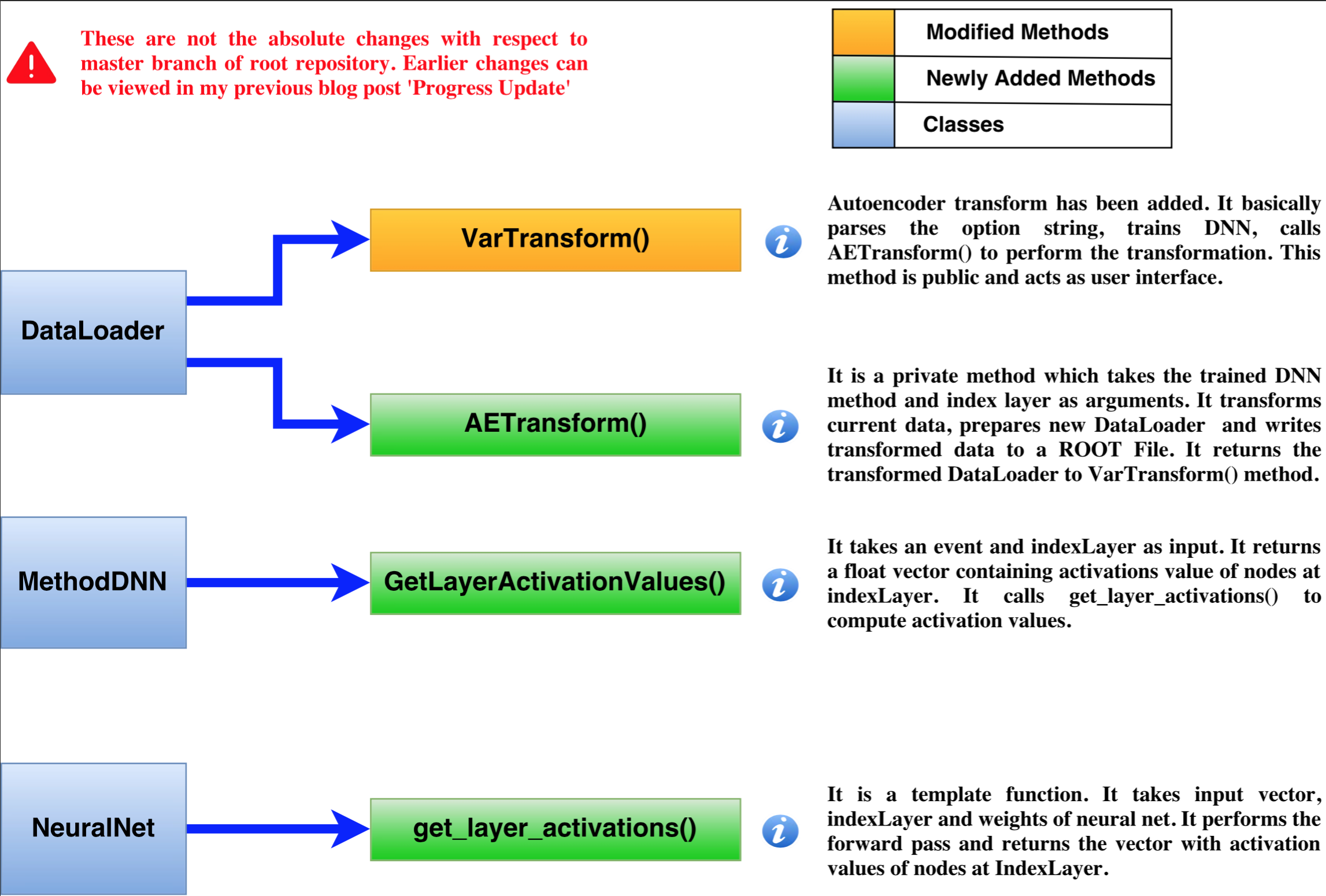
I have also created a notebook for it in my GSoC repository but I’d split it into three notebooks: Regression, Dual classfication and Multiclass Classification.
